Processors
Workbench comes packaged with methods for automating common file content extraction and analysis tasks. To help you find what you need, this guide explains the purpose of and key distinctions between different sub-packages.
Processing units
Processing units are a special class of processor, designed to offer a more optimal balance of flexibility and control to the user than could be achieved using Python functions alone:
- Lower complexity - processing units typically expect inputs to be other Workbench objects, and posses all the necessary logic to access object attributes and methods internal to the processing unit. This abstracts away many of the serialization operations, simplifying the user's code and allowing them to focus on the business logic and sequencing of operations whilst Workbench handles the rest.
- Internal state management - because processing units are aware of underlying Workbench data structures they can synchronize data inputs and outputs to/from session storage. This is helpful if a workflow process terminates unexpectedly as it can be resumed from the point of failure.
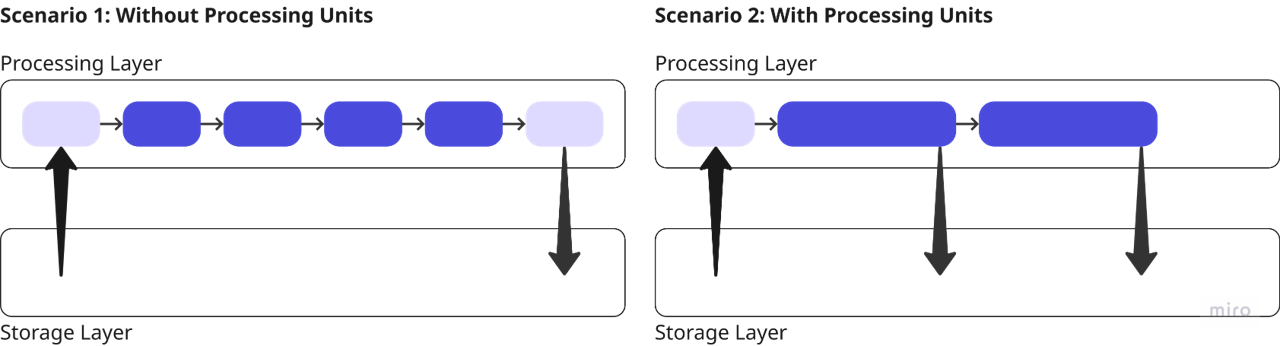
Processing units provide simpler workflows and robust state management
A processing unit can be instantiated and called as follows:
from workbench.workflows.jobs import BasicMetadataExtraction
job = BasicMetadataExtraction("Step 1 - Extract metadata ")
# Call the run() method.
# Pass the target document version and a binding to write outputs back to session storage.
job.run(doc_version, session)
Extractors
Extractors crack open information containers and convert data (or metadata) to content types that can be easily consumed by downstream jobs or steps. This normally involves converting the extracted content to plain text or image file types.
Most extractors return the extracted content in the function response, but there are exceptions to this. When the extractor queues an extraction job with a third-party service like the Autodesk Design Automation API then the content cannot be returned directly. The response from the extraction job gets written back to storage by the third-party service.
To handle this scenario, either the job that implements this extractor should implement long-polling (or other technique) to await results, or the human operator should:
- Run the extractor extract the contents
- Verify that content extraction completed successfully
- Re-initialise the session object to bind the new metadata / data from storage
- Run a second processor to consume the extracted metadata / date
Extractors can be consumed by importing from the extractors sub-package, like so:
from workbench.extractors import ...
Transformers
Transformers convert files from one format to another. Transformers are similar to extractors but are less selective in how they handle data. Examples of transformers:
- Transform any image to a downsampled .WEBP file
- Transforma a PDF to a pack of .WEBP images of each page
When creating new Workbench functions the question that should be asked is:
- Could other extractors or generators use this function to carry out more complex data preparation?
If the answer is yes then the function is a transformer and should be catalogued as such.
Transformers can be consumed by importing from the transformers sub-package, like so:
from workbench.transformers import ...
Generators
Generators use generative AI models to generate new data in response to a prompt.
Examples of generator outputs are:
- A description of a file from the supplied file content and metadata
- A vector embedding of a text input
By default, all generators use the Azure OpenAI service. The generators catalogue will be extended to leverage other foundation model providers.
Generators can be consumed by importing from the generators sub-package, like so:
from workbench.generators import ...
Classifiers
Classifiers categorise an input. Some classifiers use generative AI models to do this, while others use quantitative techniques like vector similarity search.
Some classifiers are constrained to only return a single classification (one document to one classification), whereas other classifiers return a list of suitable classifications (the latter is sometimes referred to as a tag elsewhere in Hoppa documentation).
All the current classifiers use the Azure OpenAI service. The classifiers catalogue will be extended to leverage other foundation model providers.
Classifiers can be consumed by importing from the classifiers sub-package, like so. This calatalog includes some common industry taxonomies, for example Uniclass classification.
from workbench.classifiers import ...
Searchers
Searchers answer questions about the input data they are provided with. This could be as simple as named entity extraction (places, people, things) or more complex queries like summarising key recommendations.
As with classifiers, general purpose search queries can be extended to conform the outputs to certain data types (dates, currencies) or formats ({Last Name}, {First Name}).
All the current searchers use the Azure OpenAI service. The classifiers catalogue will be extended to leverage other foundation model providers.
Searchers can be consumed by importing from the searchers sub-package, like so:
from workbench.searchers import ...
Clients
The final key concept is Client. A Client is similar to a session in that it connects into data stores, however clients offer a wider array of low-level data read/write operations and are used across different parts of Workbench for analysing files, calling external metadata extraction services, etc.
The AzureBlobSession session binding class and many processor classes have in-built methods for invoking clients using environment variables, so you usually won't have to deal with them in day-to-day use of Workbench.