Documents
Workbench is optimised for analysing unstructured and semi-structured data stored in files such as PDFs, spreadsheets and construction drawings. This guide expands on the concepts introduced in Overview.
What is a document?
A file is analysed in Workbench at a point in time. This version of the file (presumably) forms part of a longer document lineage that existed before this snapshot and will extend on into the future for as long as the document continues to be updated. However, a file could at any point be renamed or changed to such an extent as to cease to share any of the same characteristics as earlier versions. At some point the lineage must break, however pinpointing when this occurs is a grey area.
Conversely, reconstructing document lineage from a set of files will always be probabilistic (rather than deterministic). For this reason, Workbench has no Document class, but does define a DocumentVersion class. The name implies a lineage exists, which could later be re-established by using the analysis outputs from Workbench to draw equivalencies.

These files are related - but are they the same document?
Document tree
Each DocumentVersion is an access point for child information containers, as shown in the figure below. A document version has one or more sheets, each of which can hold non-graphical (text), graphical (image) and tabular (row) content.
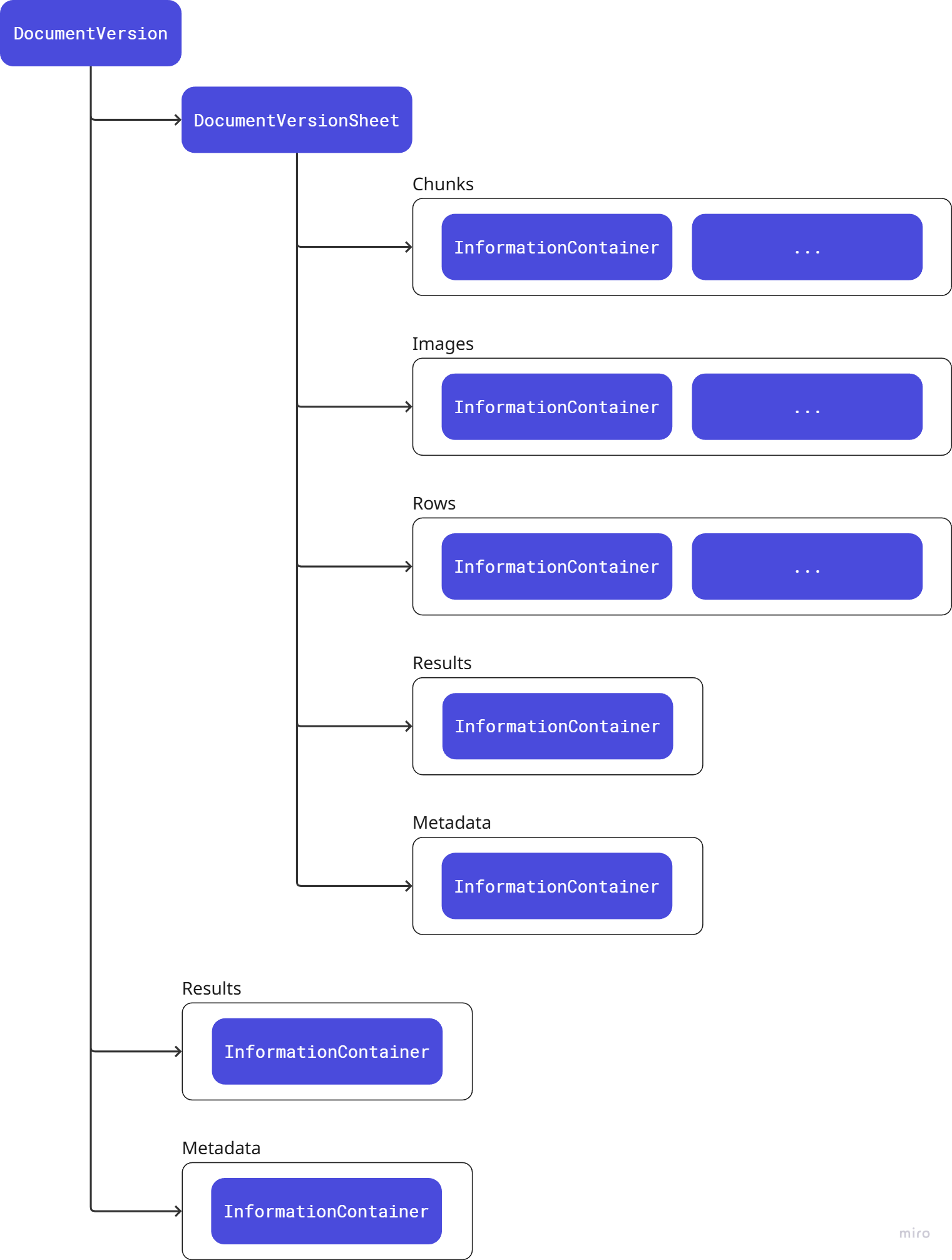
Tree hierarchy of document versions, sheets and content
Grouping content into sheets aligns with established patterns for spreadsheets, reports, 2D drawings and so on - but could also be used for decomposing more complex file types such as 3D models into parts, systems or model references.
Getting & setting content
When analysing document versions, content can be extracted from the file (or generated, in the case of document summaries) and then attached as a chid information container.
from workbench.bindings import DocumentVersion
content = "Example plain-text content"
doc_version_url = "example.com/path-to-file"
content_url = "example.com/path-to-file0_chunk.txt"
# Instantiate a document version
doc_version = DocumentVersion(signed_url=doc_version_url)
# Add an empty page to the document version
doc_version.add_sheet()
# Write the content to storage indexed under the new sheet
doc_version.sheets[:-1].bind_chunk(signed_url=content_url, content=content)
The example above considers the isolated case of a single DocumentVersion. A more likely scenario is to be interacting with document versions bound to a session - see Bindings.
In this scenario, the session binding will have indexed and assembled all source blobs into a hierarchy, ready for querying. For child information containers to be correctly bound to their parent document version with the default AzureBlobSession class they must adhere to the below naming convention.

Naming convention for child document versions - an image from/of the first sheet (page) of the file
Note
Session bindings, document versions and other information containers are only sign-posts to data - and do not have any specialist methods of their own for extracting or analysing file content. For example, before accessing the content of a sheet in a PDF, you would first need to analyse this file (using Workbench) to extract the content and bind it as a sheet chunk. Binding content makes it available for re-use in future analysis by saving it to a blob in storage.
Once a session object is initialised, sheet content would be accessed as follows.
from workbench.bindings import AzureBlobSession
session = AzureBlobSession(organization, workspace, session_id, user_id)
session.initialize()
sheet = session.document_versions[0].sheets[0]
for chunk in sheet.chunks:
# Retrieve content from storage and print
content = chunk.get()
print(content)
File results
All document versions have a results attribute for quickly accessing any files metadata generated using Workbench. Calling the get() method of the attribute should return a JSON object containing results, if one exists.
try:
raw_results = doc_version.results.get()
results_dict = json.loads(raw_results) # Parse into dict
except:
print(f'Unable to access results for {doc_version.file_name}')
File metadata
In addition to the results attribute - which binds results generated using Workbench - there is a metadata attribute for getting or setting any metadata extracted from either the file or returned by the source storage system. This metadata is uncontrolled and offered up as-is, without any guarantees on its veracity. If the source file is changed then this metadata will not be updated unless any metadata extraction step is repeated.
try:
raw_results = doc_version.metadata.get()
results_dict = json.loads(raw_results) # Parse into dict
except:
print(f'Unable to access metadata for {doc_version.file_name}')
Tip
Sheets also have metadata and results attributes, allowing for finer-grained analysis and classification within each parent information container.
Zip files
A zip file - usually marked with a .zip file extension - is an archive file format that allows multiple files and folders to be compressed and stored within a single file.
When initialising a session binding, you can control whether to index and bind all the files within the zip or only index the zip file itself. This setting can be changed on the 'Edit session' page in the Hoppa web app. Bear in mind that unpacking large zip files may considerable increase the time for your session binding to initialise.
Zip files larger than 400MB may experience difficulties initialising and should be split up into smaller archives before binding.